Cos’è il file robots.txt
Il file robots.txt è un file di testo che si trova nella cartella principale del sito e serve a comunicare ai motori di ricerca per quali pagine vogliamo bloccare la scansione.
Il file non è obbligatorio ma è sicuramente utile per la SEO dato che permette di gestire il comportamento dei motori di ricerca come Google al fine di ottimizzare le risorse del sito e del server.
Il robots.txt non è da confondere con il noindex. Quando infatti vogliamo far sì che una risorsa non venga indicizzata dai motori di ricerca non è corretto utilizzare il robots.txt. La risorsa infatti rimarrebbe comunque indicizzabile se il motore di ricerca dovesse trovarla in un altro modo. Il file robots.txt quindi si occupa di ottimizzare la scansione del sito e del crawl budget come nel caso dei contenuti duplicati.
Come si scrive un file robots.txt
Il file robots.txt viene compilato seguendo una sintassi ben precisa composta dalla dichiarazione dello user-agent e dalla direttiva che vogliamo applicare.
L’user-agent
L’user agent altro non è che il nome del crawler che i vari motori di ricerca come Google, Bing, Yandex, etc utilizzano. Ognuno di questi ha quindi un proprio user-agent ovvero un nome con il quale si presenta al sito web. Per conoscere il loro nome specifico è necessario ricorrere alla documentazione dei singoli motori di ricerca.
User-Agent: GooglebotDirettiva
Successivamente abbiamo le direttive ovvero i comandi che impartiamo ai motori di ricerca. Le direttive più conosciute sono il Disallow e Allow per indicare quali pagine debbano essere escluse oppure no dalla scansione.
Disallow: /categoria/La direttiva allow rappresenta l’eccezione mentre la direttiva disallow rappresenta la regola. Quando infatti una risorsa non è indicata nel file robots.txt i motori di ricerca presuppongono che la scansione sia permessa. La direttiva allow quindi va utilizzata soltanto quando c’è una direttiva allow per indicare una
Oltre al Disallow e Allow esiste una terza direttiva chiamata “Crawl-Delay”. Essa serve per indicare al motore di ricerca la frequenza di scansione suggerita per il sito. In questo modo è possibile evitare il sovraccarico del server.
Nonostante questa funzione possa sembrare molto utile, la maggior parte dei crawler più conosciuti sono definiti etici ovvero sono ottimizzati per eseguire la scansione senza creare problemi di sovraccaricamento del sito.
Esempi di file robots.txt
User-Agent: *
Disallow: /In questo esempio viene bloccata la scansione di tutte le pagine per tutti i motori di ricerca
User-Agent: *
Disallow: /admin/In questo esempio viene bloccata la scansione della cartella /admin/ per tutti i motori di ricerca
User-Agent: *
Disallow: /
User-Agent: Googlebot
Allow: /In questo esempio la scansione del sito viene bloccata a tutti i motori di ricerca tranne che a Google.
Inserire la sitemap nel file robots.txt
Una pratica comune e ben apprezzata dai motori di ricerca è quella di inserire l’indirizzo della sitemap xml all’interno del file robots.txt. In questo modo è possibile facilitare la scoperta e la scansione del sito web.
Per inserire la sitemap è necessario semplicemente indicarla con la seguente sintassi:
Sitemap: https://nomedelsito.it/sitemap.xmlCome testare il file robots.txt
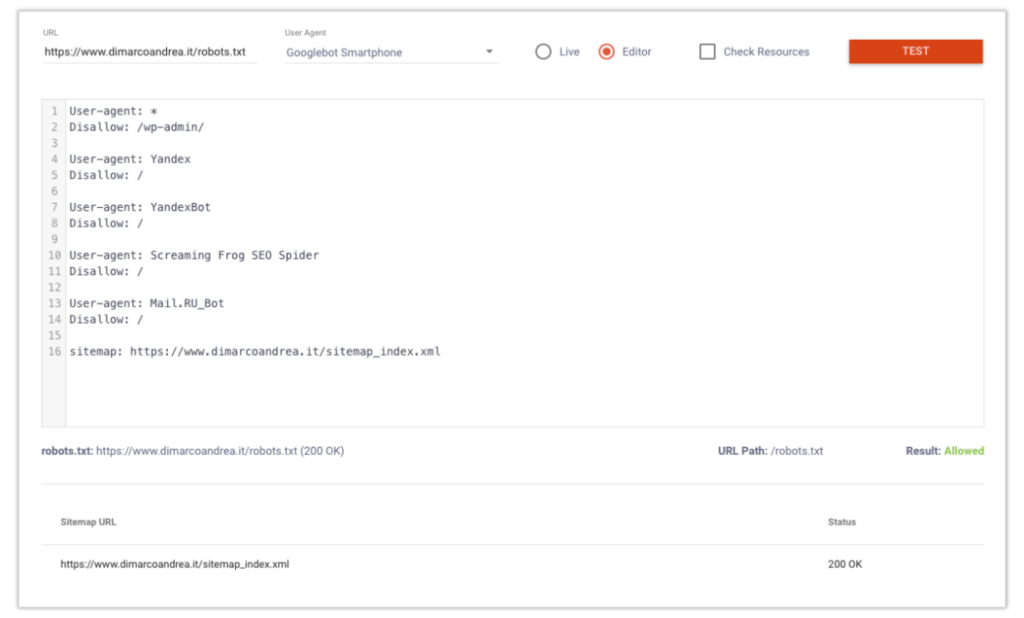
Data la natura molto rigida e l’importante del robots.txt è necessario non commettere errori di sintassi e testare il file ogni qualvolta esso venga modificato. Per controllare che il file robots.txt sia effettivamente funzionante è consigliabile utilizzare il tool online di TechnicalSeo che permette, scegliendo la pagina e l’user-agent, di controllare se il crawler è bloccato oppure no.